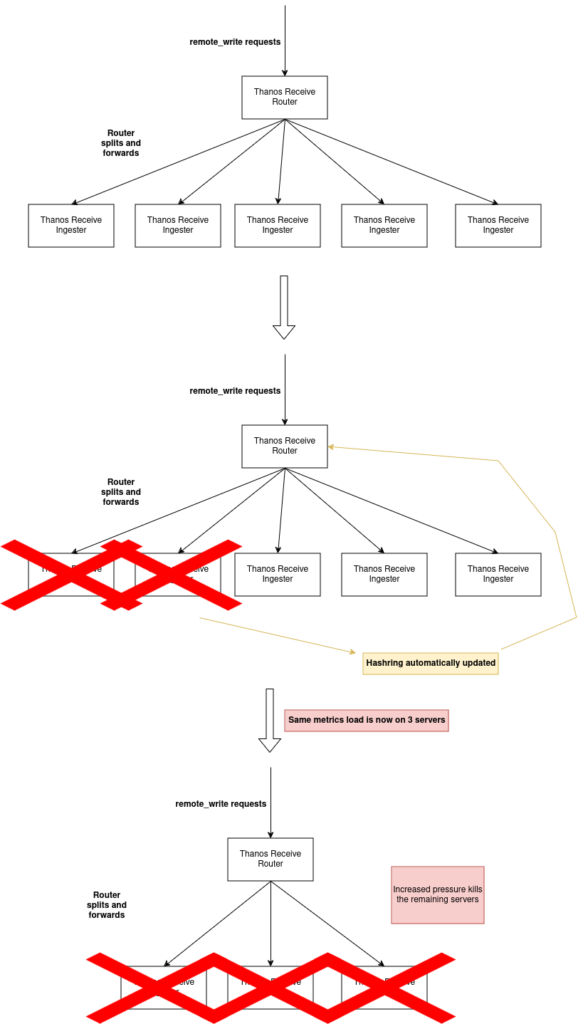
Hashrings are everywhere in distributed systems. Combined with a write-ahead log that uses an unbounded amount of RAM during WAL replay, they are a terrible idea. If there is a constant stream of metrics coming into Thanos, you want to push back on the producers of those metrics in case of one or a few node’s downtime. Having a dynamic hashring i.e. a hashring that immediately updates as soon as it notices that one node is down, prevents that. The same stream is now going to fewer nodes. And so on until, most likely, your whole stack collapses. In practice, this means that you should not remove a node from the hashring if it is unhealthy or unready.
To say it in short: the problem is unbounded memory usage. It can be rectified by limiting memory usage or by not having a dynamic hashring.
A picture is worth a thousand words so let’s show what it looks like:
The same thing could happen with Loki. However, there you can specify the maximum amount of memory that it can use during replay. If you are running into issues then consider lowering this setting as per your requirements.
wal:
[replay_memory_ceiling: <int> | default = 4GB]