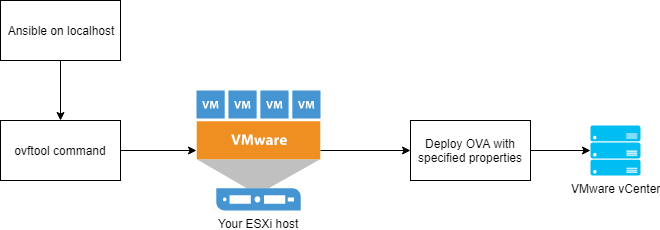
![]()
Since the recent acquisition of GitHub by Microsoft, a lot of people and companies are migrating to GitLab. The GitLab offering is especially attractive to early-stage start-ups since they offer free 10000 CI minutes or, in other words, 10000 minutes on their CI servers. It is easy to move over the workload to your own Kubernetes cluster once you run out of them – there is an easy-to-use user interface available where you could do that with just a few clicks.
Because of that, some kind of way is needed by companies to implement the release process on GitLab. Obviously, there are a lot of great solutions out there. However, let me present the process that I thought of. Besides the primary requirements of all releases processes, this one also takes minimal resources in terms of money and time because it is implemented directly using the GitLab CI functionality.
Are you interested? Let’s begin.
The overarching idea of this release process is to use the GitLab’s embedded Docker registry and the tagging functionality. Differ

ent branches are going to be used for different stages of the release process – development images, unit under test (UAT) images, and the final images. Those different branches will also contain information about what kind of binaries to pull into the resulting Docker image. After a certain number of iterations, the development image is promoted to the UAT image. After some testing by, for example, QA engineers and housekeeping (e.g. some documentation needs to be updated or clients informed), they will finally be released into the wild by retagging the image with the final version tag.
Let’s drill down into the finer details.
All GitLab repositories at this moment have a free, embedded Docker registry enabled. I recommend using a separate repository for this release process – maybe you do not want to always release a new development image once new code gets pushed. Also, you might accidentally one day conflate the branches used for the release process and the development. Obviously, you could “protect” them but still, I don’t think it is worth it.
First of all, you need a Dockerfile that will be used to build the image. This guide will not talk about it, it’s up to you to figure it out. My only recommendation is to think about it as if that image is going to be released to your users i.e. it has to have everything.
Afterward, you should create a .gitlab-ci.yml file in the root of your repository and start building the blocks for the docker image build. You should begin by specifying that it’s a docker-in-docker build and in the before_script part, you need to log in to the GitLab registry:
image: docker:stable variables: DOCKER_DRIVER: overlay2 services: - docker:dind stages: - build before_script: - docker info - docker login -u gitlab-ci-token -p $CI_BUILD_TOKEN registry.gitlab.com
The only stage that is needed is the build stage since that is the only thing we want to do in this repository. Adapt this for yourself if you want to embed the release process inside of your code repository (if you have some kind of .gitlab-ci.yml).
overlayfs supposedly (GitLab documentation says that) gives a better performance in docker-in-docker thus use it. We will not go into the results of benchmarks of different filesystems.
After, the image building action needs to be specified as part of the build stage in the .gitlab-ci.yml file. This is how I recommend you to do it:
build_image:
only:
- master
stage: build
script:
- "docker build -t companyname ."
- docker tag companyname registry.gitlab.com/companyname/coolproject/companyname:latest
- docker push registry.gitlab.com/companyname/coolproject/companyname:latest
Replace companyname in this snippet with your own company name. Also, coolproject should be the name of your project in GitLab. Most people have named their main branch as master but change that again if it does not fit your case.
Furthermore, create branches named uat and release. They both will serve to represent the different parts of the release process outlined earlier. Perhaps in those branches you should leave a README.md file which tells how the release process works.
In those separate branches, you will have a slightly modified .gitlab-ci.yml file which will essentially just pull a Docker image, retag it, and upload it back to the registry.
In the uat branch, in the .gitlab-ci.yml file you should have something like this (the other parts are skipped for brevity):
variables:
DOCKER_DRIVER: overlay2
CURRENT_IMAGE: registry.gitlab.com/companyname/coolproject/companyname:latest
UAT_IMAGE: registry.gitlab.com/companyname/coolproject/companyname:0.0.1-UAT
stages:
- retag
pull_latest_and_tag_uat:
only:
- uat
stage: retag
script:
- docker pull $CURRENT_IMAGE
- docker tag $CURRENT_IMAGE $UAT_IMAGE
- docker push $UAT_IMAGE
As you can see, the newest development image is simply pulled, tagged, and uploaded back to the GitLab’s Docker registry.
Finally, in release the same essentially should be used except that this time we will tag $UAT_IMAGE with the tag 0.0.1:
variables:
DOCKER_DRIVER: overlay2
CURRENT_IMAGE: registry.gitlab.com/companyname/coolproject/companyname:0.0.1-UAT
RELEASE_IMAGE: registry.gitlab.com/companyname/coolproject/companyname:0.0.1
stages:
- retag
pull_latest_and_tag_release:
only:
- release
stage: retag
script:
- docker pull $CURRENT_IMAGE
- docker tag $CURRENT_IMAGE $RELEASE_IMAGE
- docker push $RELEASE_IMAGE
In the end, you will be left with a Docker image with a proper tag which went through the usual release phases: development, extensive testing, golden release. I also recommend locking the uat and release branches so that someone would not accidentally push something into those branches and overwrite your Docker images.
I hope this tutorial was useful. Happy hacking! Let me know if you run into any issues.