PromQL kind of became a de facto standard of querying metrics. PromQL is the querying language of Prometheus. Over the recent years, a lot of different vendors started making products that are “compatible” with Prometheus. Julius Volz covers the general aspects of compatibility in his blog at https://promlabs.com/promql-compliance-tests/. However, it would be interesting to look at the technical differences between PromQL engines embedded in each product. I will be mostly looking at the differences between engines in terms of how much they support concurrency, distributed evaluation features such as pushdown or general evaluation over many servers, optimizations, and how close they are to the vanilla engine.
Also, notice that I am not impartial about this topic – I have been working on Thanos and Prometheus for a few years now so I might miss some details and be biased about certain design decisions. Please let me know any suggestions in the comments so that I could amend this post.
We will compare these versions in this post:
Without further ado, let’s start with the original version – the Prometheus PromQL engine.
Prometheus PromQL engine
It’s quite simple in comparison to the other engines and it feels like this simplicity has inspired other engines. Most of the things happen inside of the (*Engine).exec() function and the evaluator struct. Another main part of the engine is storage.Queryable – it allows getting metrics from some kind of storage. This means that it is easy to put the engine on top of anything that allows retrieving time series data.
It works by evaluating the AST (abstract syntax tree) nodes recursively. The AST nodes are generated after parsing the user’s query. For example, there is a type *parser.Call that represents a function call. That way while evaluating the query recursively, the engine is able to understand what to do. If the function accepts some arguments then all of those arguments are evaluated recursively and so on.
The main strength and at the same time drawback of the engine is that it works by looping through all series returned by a vector selector, and then through all of the steps serially. This makes it easier to capacity plan usage because one tenant’s query will never use more than one CPU core. On the other hand, it’s not rare for modern servers to have hundreds of cores hence it doesn’t make much sense to not use all of the other cores. For example, we could decode different time series concurrently.
Over time it has been optimized significantly but even with all of that, it is hard to compete with other options in terms of sheer performance. This is in part due to the fact that some of the optimizations might not even be possible because the engine tries to be as general as possible. For example, apparently, there are such storage.Queryable out there that heavily depend on the correct label matchers or, in other words, if label selector optimizations were to be applied then it could return completely different results even if the different requests would seem semantically identical to a person unaware of those use cases. See the link issue for more discussion.
thanos-community/promql-engine
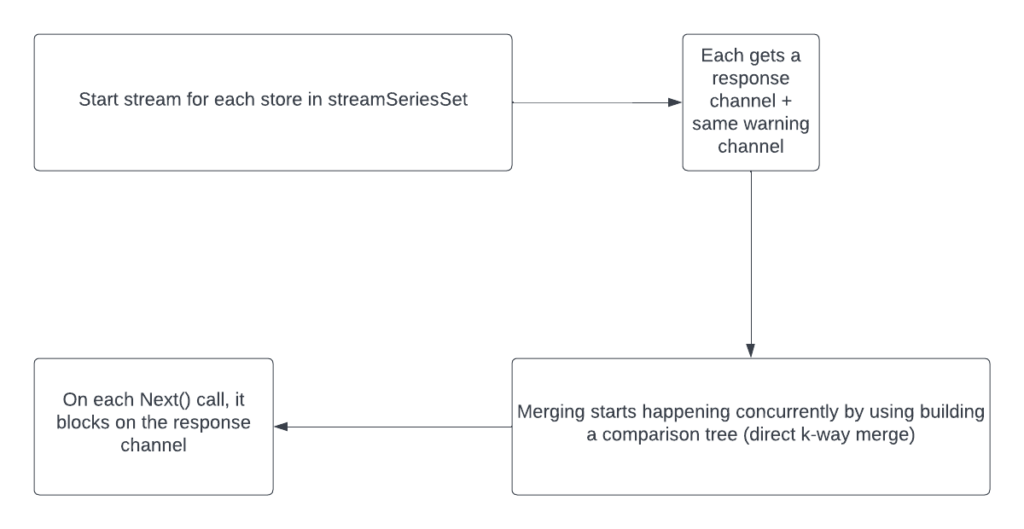
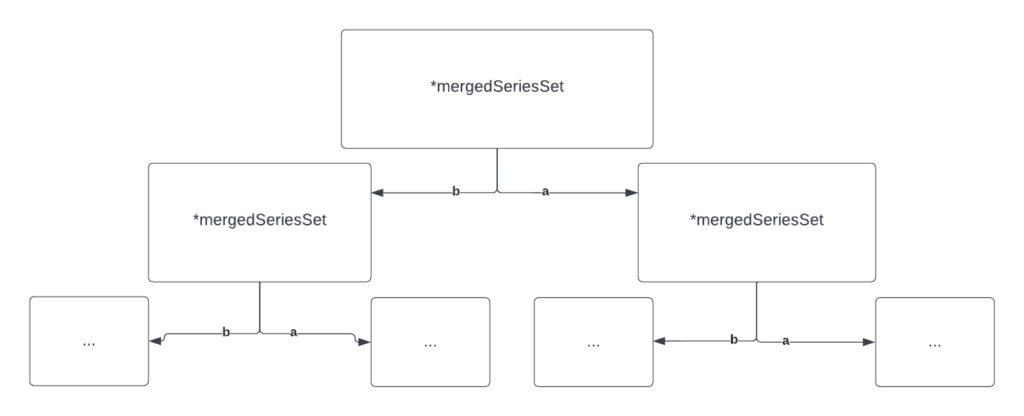
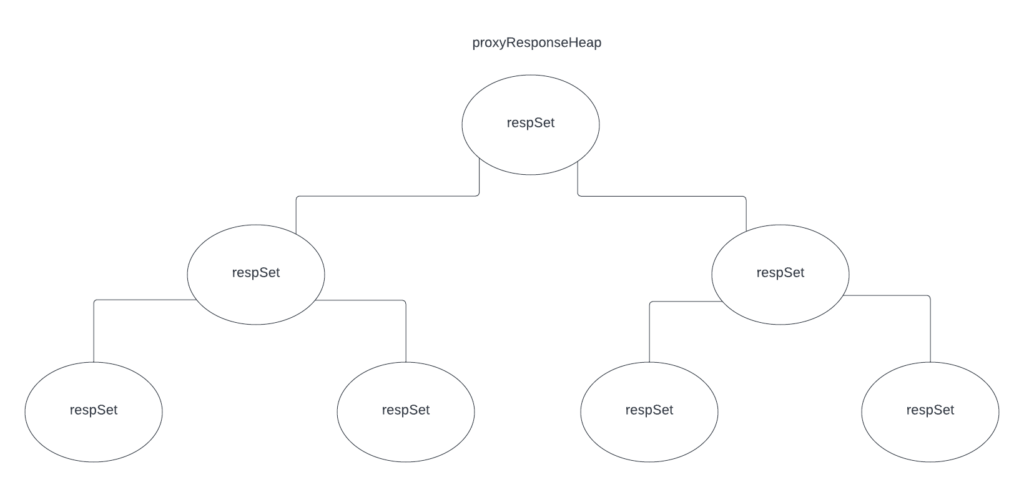
Let’s enter the concurrent era. promql-engine is based on the Volcano model. In this engine, the parsed query’s AST tree by vanilla Prometheus code is used to construct a logical plan of different so-called operators. All of those operators are composed via the method Next() that returns a result of that operator’s work. This means that at the top level, it is enough to continuously call Next() to get the response to the user’s query. It is possible to construct such operators that will perform their work concurrently.
One challenge is to know how much memory needs to be allocated in advance. That’s why there’s also another method called Series() that returns a slice of sets of labels. It allows operators to know exactly how much memory is needed.
Since everything is streamed and multi-threaded, it means that peak memory consumption is a bit higher. Since most multi-tenancy nowadays is implemented by putting services into different logical computers (they can be containers, virtual machines, etc.), I don’t think it’s such a big problem.
I have personally seen query durations drop 50 – 70% just because the whole query engine is written with multi-concurrency in mind in comparison to the vanilla engine, not to mention all of the other optimizations.
However, the engine is still a bit premature. It lacks support for certain functions or set operations. But, it will automatically fall back to the vanilla PromQL engine in such a case. This allows for experimenting with the new engine quickly.
Distributed execution is being worked on. It should work functionally the same as the pushdown in promscale and it will support many more aggregations. 🤞
Kudos to Filip, Ben, and all of the other people & companies involved in this project!
All of the following engines are unchartered waters for me so please excuse my ignorance if I have mislooked something during my research. Add a comment with any suggestions!
VictoriaMetrics engine
It seems like the VictoriaMetrics engine is written more or less like the Prometheus PromQL engine in the way that a tree of expressions (nodes) is constructed and the top-most expression is then evaluated. This is the goal of simplicity in play.
It contains some concurrency features – for example, all of the arguments to a function are evaluated concurrently. It also has a lot of awesome optimizations such as the pushing down of matching label sets on the right-hand side in a binary expression. You cannot find such optimizations in any other engine. In my opinion, they should appear in thanos-community/promql-engine sooner or later. At least I want to see them.
vmselect also seems to work in a rudimentary way – it asks all vmstorage nodes that it knows about to get metrics that are needed for a given query. Here’s the code of this functionality: https://github.com/VictoriaMetrics/VictoriaMetrics/blob/0e1c395609d4718fbd8dc7bef30bc73160cdcf1b/app/vmselect/netstorage/netstorage.go#L1575, https://github.com/VictoriaMetrics/VictoriaMetrics/blob/0e1c395609d4718fbd8dc7bef30bc73160cdcf1b/app/vmselect/netstorage/netstorage.go#L1617-L1632. Also, it has a cache for data that has been already retrieved in the past which is nice: https://github.com/VictoriaMetrics/VictoriaMetrics/blob/207a62a3c22282ca02521b7ab9a09c9c96d15764/app/vmselect/promql/eval.go#L1014-L1015.
M3DB engine
My initial impression is that it is written much cleaner – there are lots of small functions that do one thing well, and the underlying data structures “stand out” much more. It applies more or less the same optimizations as the vanilla PromQL engine except that it is more concurrent. For example, data is fetched and transformations are applied concurrently: https://github.com/m3db/m3/blob/37c5a40d655a7cdde9cbc3725b4f377ded761d53/src/query/storage/fanout/storage.go#L303-L317, https://github.com/m3db/m3/blob/37c5a40d655a7cdde9cbc3725b4f377ded761d53/src/query/executor/state.go#L184-L192.
Also, interestingly enough, m3db supports switching between their own engine and the vanilla engine using headers: https://github.com/m3db/m3/blob/37c5a40d655a7cdde9cbc3725b4f377ded761d53/src/x/headers/headers.go#L41-L43. This would probably make sense in the Thanos project – we could have this instead of having to restart the whole process to change a command-line flag.
The story of parsing is quite similar to thanos-community/promql-engine – original PromQL parser is used to generate a tree that is then walked, and from it, another tree is built: https://github.com/m3db/m3/blob/37c5a40d655a7cdde9cbc3725b4f377ded761d53/src/query/parser/promql/parse.go#L176.
Promscale
From the onset, a completely different beast compared to others because it runs on PostgreSQL and TimescaleDB. However, it actually uses the same, old Prometheus PromQL engine under the hood: https://github.com/timescale/promscale/blob/ba0b695799594d87540ae13acfded80bba5eb730/pkg/pgclient/client.go#L290. The difference is that it is a bit modified to make it fit. Here’s the Select() function that returns data from the underlying PostgreSQL database: https://github.com/timescale/promscale/blob/ba0b695799594d87540ae13acfded80bba5eb730/pkg/pgmodel/querier/query_sample.go#L27. It tries to pushdown everything that it can with the help of extra hints about the currently evaluated node: https://github.com/timescale/promscale/blob/ba0b695799594d87540ae13acfded80bba5eb730/pkg/pgmodel/querier/query_builder.go#L250. This improves the speed of evaluating because not all data needs to be sent to a central querier. Here’s a comment explaining the same: https://github.com/timescale/promscale/blob/ba0b695799594d87540ae13acfded80bba5eb730/pkg/pgmodel/querier/query_builder.go#L384-L390.
Here’s how all of the characteristics would look in a table:
| Engine’s name | Distributed features | Parallelism | Is it close to the vanilla engine? | Optimizations |
| Prometheus vanilla engine | 🟡 (everything is local, minimal distributed features can be achieved with “smart” iterators; see pushdown commit) | ❌ (everything is single-threaded) | ✅(the original engine) | N/A, vanilla engine |
| thanos-community/promql-engine | 🟡 (same pushdown comment applies; sharded evaluation is being worked on and there’s a beta version available in Thanos) | ✅ (everything is as parallel as possible) | 🟠 (everything written from scratch except that the PromQL parser is used just like in m3db) | 🟠 (merging Select()s, pushing down label matchers, and more; still a bit rough around the edges, there are some more things left to do like lazy set operations) |
| promscale (discontinued) | 🟡 (the engine pushes down the surrounding aggregations to the data nodes as much as possible (only delta, increase, and rate are supported); it also only gets the last point in a vector selector window) | 🟡 (it uses the vanilla Prometheus engine with pushdown changes; the underlying PostgreSQL engine is very optimized) | 🟡 (modified vanilla engine with aggregation pushdown to PostgreSQL) | ❌ (doesn’t seem like there are any optimizations in the PromQL engine besides the distributed query features) |
| m3db | ❌ (seems like no matchers are pushed down to storage nodes and everything is done in a central location) | ✅ (fetching and transformations are done in parallel) | 🟠 (it re-uses the vanilla PromQL parser to generate a direct acyclic graph of internal nodes similar to thanos-community/promql-engine) | ❌ (doesn’t seem like there are any optimizations in the PromQL engine) |
| VictoriaMetrics | ❌ (RPCs are used to retrieve all needed data before evaluation in the vmselect node) | 🟡 (binary operation’s operands are evaluated in parallel; function args are evaluated in parallel. Seems like fetching is done serially in advance before a parallel evaluation) | ❌ (completely custom PromQL/MetricsQL parser) | ✅ (state-of-the-art query optimizations e.g. lazy or operator and so on) |
All in all, it doesn’t seem like there’s a clear winner. Some of the engines are better in one regard but worse in others. Perhaps it would have been a better situation for users now if everyone would focus their effort on one engine instead of reimplementing it however I do understand that changing the engine in Prometheus itself might be hard because it must accommodate all of those weird use cases that probably only occur to 1% of users. We can probably draw some parallels to the startup world – over time companies and software grow with a bunch of functionality that becomes too complex to use or there is some functionality that is used by just a few customers hence the functionality is removed. Then, some hot, new startup occurs that tries to solve the same problem in a better way with software that is more opinionated and easier to use for some use cases. Thus, maybe the engine in Prometheus v2.x has outlived its usefulness and Prometheus v3.x might be long overdue with some “legacy” features removed to pave the way for a truly scalable PromQL engine.
Also, while writing this post, Promscale has been discontinued as a project. That’s a bit sad because it had some great ideas, in my opinion. And this serves as a sign that users should be sometimes wary of completely vendor-controlled open-source projects because the support for it might just disappear one day or something might change drastically.