Recently I have read a quite popular book called “The Design of Everyday Things”. I feel that with software slowly taking over more and more parts of the world, we could say that it also became an everyday thing and that we should design it like that. This blog post will be about it.
There are certain, general design principles that were explained in that book which we should apply to the process of programming in general.
We will talk about them in terms of APIs – the programmable interfaces of applications. It is a form of an interface and one of the most prevalent ones. Having these design principles in mind should help us design better APIs.
I feel that a lot of these concepts were already expressed in books such as “Clean Code” by Robert C. Martin but nonetheless, it is interesting to look at those principles from the APIs perspective and from the general design of items – hopefully, we will learn something new.
Mode Errors
The first thing I want to start with is what Don Norman calls a group of errors called “mode errors”. Essentially, it occurs when a device can be in many different states and then the user becomes overwhelmed: they simply do not know which mode they need to use or what it even is at the moment. In the same regard, if we were to treat an API as an everyday thing, we should strive to get rid of these type of errors.
This means that the number of combinations of different values an API call can have must be reduced to the minimum. To be more precise, your API should try to compute as much stuff as possible unless it becomes an actual impediment to the performance. Thus, we should opt to calculate values which are of O(1) or, at most, O(n) complexity.
Also, the values themselves, if they are enumerations, should not have duplicate meanings, and minimal types should be used that are able to hold the needed information. This example may seem a bit superficial but, for instance, if your API that uses JSON only needs to accept numbers then it is probably much more useful to actually use a number type instead of accepting a string and only then converting it into a number.
We need to focus on our users and understand that they are constantly being interrupted by others, the attention span might not be as big, and that it is much more complex for a fresh person to understand all of the different modes that your API might be in. There needs to be a clear signal of state.
Communicate When Things Go Wrong
Feedback and feed-forward cycles are very important. This may seem a bit obvious but this still happens from time to time. In essence, we should always report errors when possible to the caller when something goes wrong (and it does inevitably). This feeds a bit into the previous tip in that the state should always be clear.
Practically, I think it means that your programming language should ideally support sum types which would force you to check for errors and report these errors accordingly to the caller of the function. For example, Rust has the std::result type for this exact purpose.
This also means that if you are making a library that is supposed to be re-used by others then it should absolutely not abruptly make the whole process exit. For example, calling os.Exit(1) in a Go program when something goes wrong is a huge no-no.
This one glog library is notorious for that. It has been written some time ago so it does not follow this recommendation. You can see that if it fails, for example, to rotate files inside of the library then it exits the whole process. But why would it do that at all? Let’s say os.Stderr is closed so the user would not know at all why their program might exit. The rotation could be nice but it should probably be left to external and well-tested programs.
Discoverability and Understanding
The next thing to keep in mind is to make easy to understand what kind of things we can even do with the API mostly after performing some actions. For instance, if you are designing a REST API then you will use verbs according to their meaning and your API will support easy-to-understand objects. This will make it easy for your users to intuitively discover what is possible.
Another common pattern is to provide links in your API responses to other things that can be done. For example, the Hypermedia API language (HAL) format uses (optionally) the _links key in the JSON responses to indicate where else the user could go to do certain actions. Or, usually APIs nowadays include pagination links in the response. The client then can go on to those URLs to do those respective actions.
In essence, it is conceptually the same as having some kind of links or buttons in real-life interfaces or response dialogues with simple verbs which would do certain actions. This is the same principle adopted for API designs.
Affordances And Signifiers
Norman formulates affordance as a property of an object – that you can do something with it, and signifiers “tell” the human what kind of operations are possible. This is in a way connected to the former point of “Discoverability”, however, not completely. Signifiers should be visible to the users from the outlook, without having performed any actions. What this means for us that we need to have some kind of way to increase the number of signifiers.
Usually, this comes up as having well-formed documentation. Nowadays it is very common to include simple interfaces like Swagger which signify to the user what kind of actions are possible.
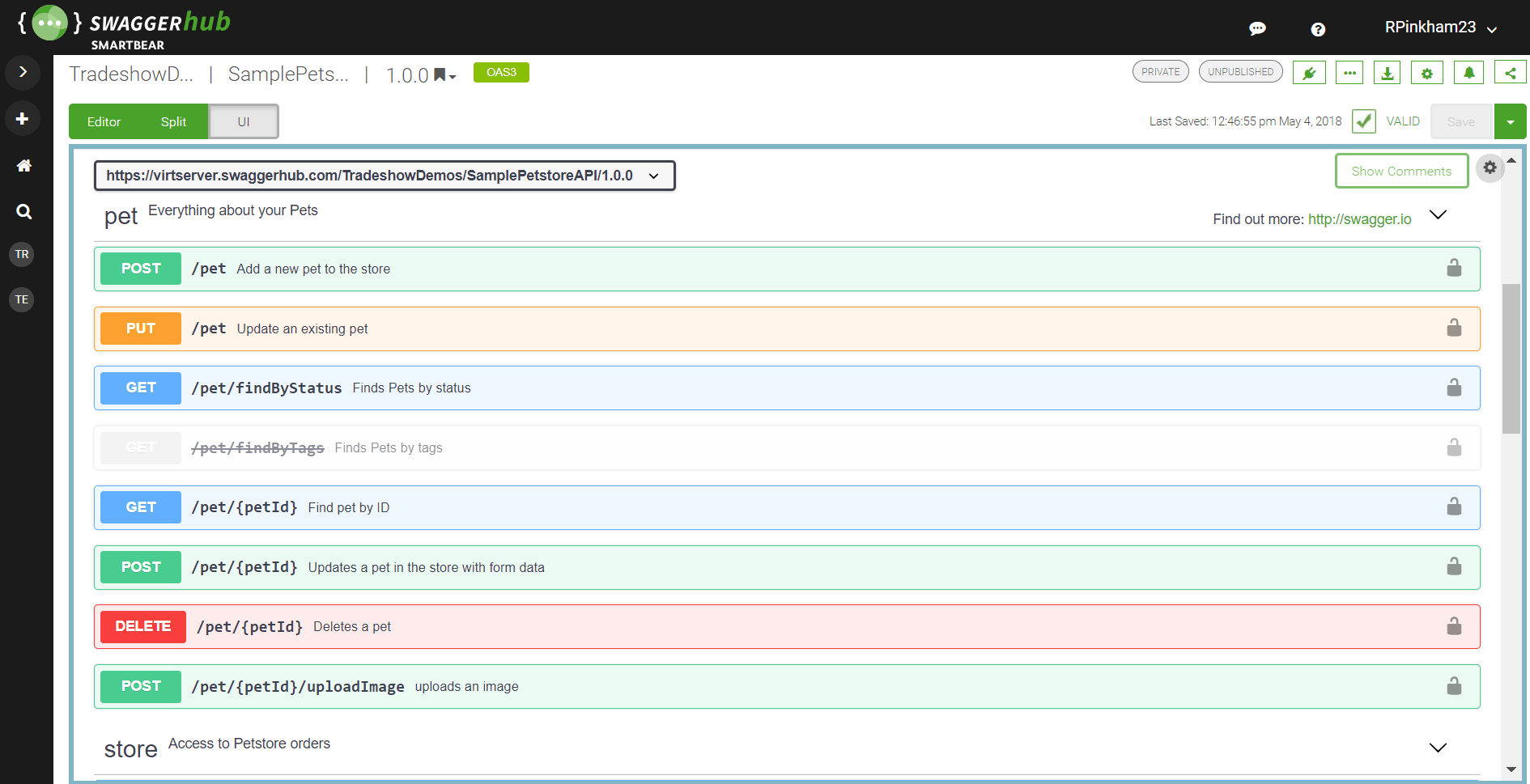
As you can see, all of the possible actions are presented as a neat table. This tells the user what can they afford to do via using the API. There are, of course, competing solutions but if not Swagger then we should still strive to have some kind of interface like this.
Because if there is not then it becomes hard to understand what the API lets us do without reading the actual source code. And that is like having to get into the mind of the designer/developer of the thing which is what we are trying to avoid. Ideally, this interface should be generated from the source code itself. For more information, refer to Chapter 29 “It’s Just A View” from the book “Pragmatic Programmer“.
Constraints
Constraints allow the user to just intuitively know how different parts should fit together. We can think of this in terms of a standard library of functions/classes that some framework, your API provides.
In my opinion, a good example of this is the Python mantra:
There should be one – and preferably only one – obvious way to do it.
Some people might argue that with all of the new additions (and the old relics in the Python’s standard library) this is not so true anymore but still, we should strive to achieve this.
As always, the goal is to reduce the likelihood of an error and accidental complexity. If we were to have more than one way of doing things then we would start having questions like:
- which functions or class should we use in what case?
- which way has the bigger efficacy?
- and so on.
On the other hand, the antithesis of this, in my belief, is the C++ programming language. Over the years it had accumulated a lot of historical cruft due to always trying to be backward compatible and other reasons. Modern C++ language style guides even recommend you to only use a subset of the language itself. That is how bad it became. For instance, it is forbidden to use exceptions even though they are in the language itself.
Mappings
Last but not least, Don has introduced a concept of mappings. The actions that are available to the user should map logically to the items that are provided to them. He gave an example of gas controls on a stove – the controls should clearly be connected to the different outputs.
In our case, you probably would not want to include random methods in your API specification which are completely unrelated to it. Also, the methods should do operations only on items that you have passed to it. Otherwise, you might be running into the risk of creating unclear relationships between different parts of your API.
Conclusion
I liked this book a lot – since the start, I was completely hooked by it and it was a page-turner. The paradoxical book cover caught my eye and I just had to read it.
It has brought me some perspective over software design from the point of view of the general design of things around us that we use every day. With software becoming more and more prevalent, I think that the concepts introduced here will be more widely adopted and respected.
