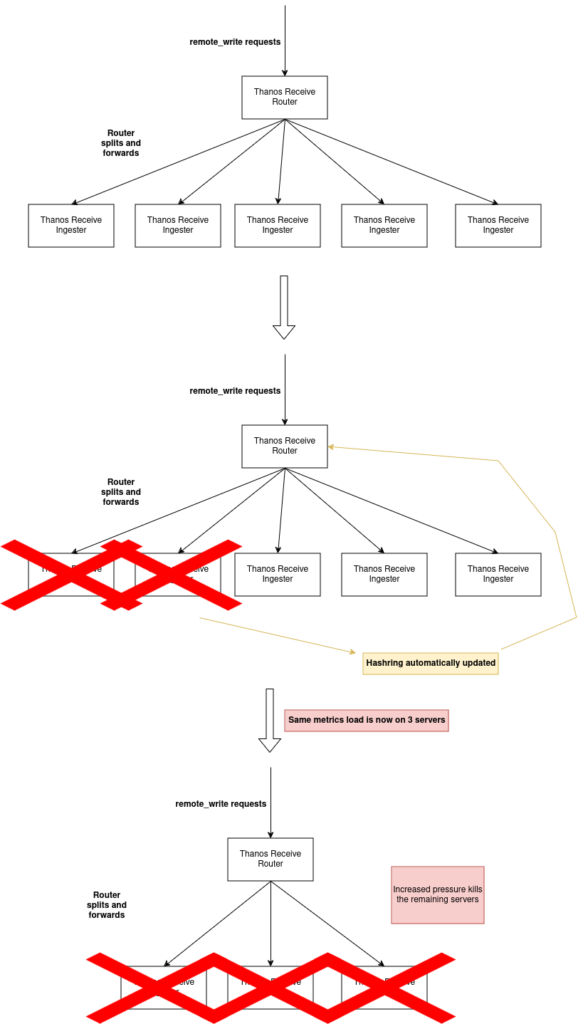
It all started in, I believe, the eventful year of 2001. I was 6 years old. Our family was lucky enough to get our own first personal computer! Completely for us and used by all members of our family back then. I consider that to be incredible luck given that Lithuania recently regained its independence after the Soviet occupation. I think we got internet connected to our house around 2003 so for a few years we were offline. My mom was still studying back then and she used the computer a lot for her studies. But me and my brother mostly used it for entertainment – music, games, videos. Someone left some pre-installed games like Dave Mirra Freestyle BMX and Worms Blast on the computer, and we played the heck out of them.
My brother at the same time was also learning to program at school. The pupils were programming using Comenius Logo. If you have never heard of it, the best way to describe it is that you can control a turtle using commands, loops, functions, and so on. You can make it draw fractals, create games, and much more! It’s deeply entertaining. I would compare it to something like Scratch.
Here’s how Komenskio Logo, the Lithuanian version of Comenius Logo, looks like on my Linux machine with WINE:
I saw my brother programming some kind of assignment back then and it caught my attention. I remember that I was instantly hooked. You can think of some random commands and then the turtle goes ahead and executes them? Wow, that’s so cool!
Fast-forward a few years and now we were on the internet. IRC was very popular back then. And finding other people to play games with on channels was a very popular thing back then. The IRC channels for finding other people to play Counter-Strike 1.6 with were very populous. I played Counter-Strike 1.6 for many years. I remember that I was trying to automate some things in mIRCScript because I was curious about how others people made these bots that responded to what other people typed.
And all of this led me to find another thing – Linux. I wanted to try to run my own CS server. This combined with my interest in how mods for CS are made fanned the programming fire inside of me.

This was a disk of Ubuntu that I burned. Ubuntu 8.04 was the first GNU/Linux distribution I have ever tried. I had an ATi card back then and it was a horrible experience. fglrx worked somewhat but there was no video acceleration so watching videos was painful. I was constantly juggling back between Windows and GNU/Linux. For gaming, videos – Windows, for other stuff – Linux.
As far as I remember, the rest is history. I picked up C++ for competitive programming and started dabbing in other computer software stuff like fiddling with routers and so on.
Remember that there is no ideal path – everyone is different. I wanted to share mine in case it inspires someone to also pick up programming. I believe the key is part is that you should find something that interests you. If something does interest you then keep going at it and you will succeed.