Recently I ran into a surprising ZSH performance bottleneck while editing my .zshrc. Because it gets loaded every time a new shell comes up, I have noticed the issue pretty fast. I quickly started digging into the problem. Apparently, this surprising behavior concerns appending new elements to an array. I did not have a huge file that I was trying to read, only about 6000 elements or so. But still, it had a significant impact on how fast the Z shell was able to start up.
Imagine a simple loop such as this:
#!/bin/zsh
while read line; do
echo "${line}"
done < ~/somefile
And ~/somefile has been prepared with:
#!/bin/zsh
for i in `seq 1 8873`; do
UUID=$(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 32 | head -n 1)
echo "${UUID}" >> ~/somefile
done
Then, let’s read the same file into an array with two different scripts:
#!/bin/zsh
arr=()
while read line; do
arr=(${arr} ${line})
done < ~/somefile
#!/bin/zsh
arr=()
while read line; do
arr+=(${line})
done <~/somefile
Could you guess which one is faster? If your answer is the 2nd one then you are correct. At least on my machine:
$ time ~/testcase_fast.sh ~/testcase_fast.sh 0,17s user 0,11s system 98% cpu 0,279 total $ time ~/testcase.sh ~/testcase.sh 15,68s user 0,95s system 98% cpu 16,881 total
A simple ltrace(1) comparison reveals where the time is actually spent:
% time seconds usecs/call calls function ------ ----------- ----------- --------- -------------------- 34.49 17.657872 60 292810 read 25.07 12.833696 43 292815 mbrtowc 8.41 4.304812 60 71076 sigprocmask 7.80 3.994101 43 91362 strlen 6.99 3.580468 43 82299 strcpy 4.04 2.066031 43 47979 malloc 3.78 1.936972 42 45209 free ...
And the “slow” version (not the full run here since it takes a very long time however the picture is clear):
% time seconds usecs/call calls function ------ ----------- ----------- --------- -------------------- 28.21 177.575768 44 4006596 strlen 28.11 176.938217 44 4000420 strcpy 14.16 89.127826 44 2002599 malloc 14.01 88.177566 44 1996322 strchr 13.99 88.058532 44 1999451 free 0.62 3.915208 59 65835 read 0.45 2.844029 43 65841 mbrtowc ...
My original assumption was that ZSH would “understand” that I am simply adding a new element at the end and thus avoid copying. To be honest, I haven’t even suspected this part when I had started investigating this. However, clearly, that’s the culprit. It seems that in the slow version the Z shell is constantly allocating, copying, and freeing memory which takes most of the time – more than 50% of the time. 😱
Truth be told, I have copied this code at first from StackOverflow and adapted it to my own needs:
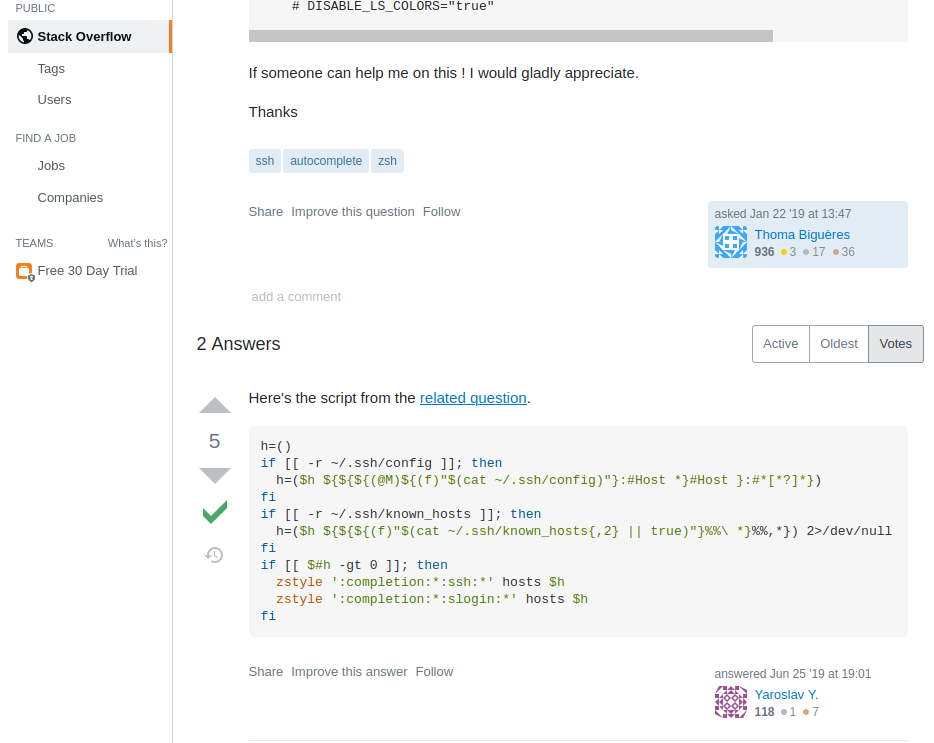
So, this is yet another reminder not to have too many presumptions about how something works and that snippets of code on the Internet are not necessarily of the best quality.
Strictly speaking, we couldn’t probably even say that we are appending an array in the slower version because the += operator is not being used. On the other hand, the effect is the same so I think it is OK to use the word append here in the general sense.
All in all, you should always use += when appending elements to an array! I hope this helps! Let me know if you have any comments or suggestions!