
Time and time I see people who follow all these random online tutorials and then when something does not work they become dazed and confused. “Why this does not work? But this tutorial shows that it should work” – I see similar questions occasionally in various forms on forums and IRC. I think people do not realize that there is some kind of hierarchy of trustworthiness of information sources. We should be conscious of that hierarchy when looking for information and remember it when we notice that something is not correct or up-to-date.
In my opinion, the field of studying history has already nailed this down. They have what is called the primary and secondary sources of information. Primary sources provide direct evidence about an event, object, person, or work of art. The latter thing is similar but they talk and analyze the primary sources [1]. It seems to me that we can draw a parallel between this and the information sources that we use to study programming. However, instead of having a simple distinction between primary and secondary sources, a hierarchy is more suitable because we are talking about researching a thing that we have in front of us at present and we can experiment with it. The only question that remains is: how does the hierarchy look like?
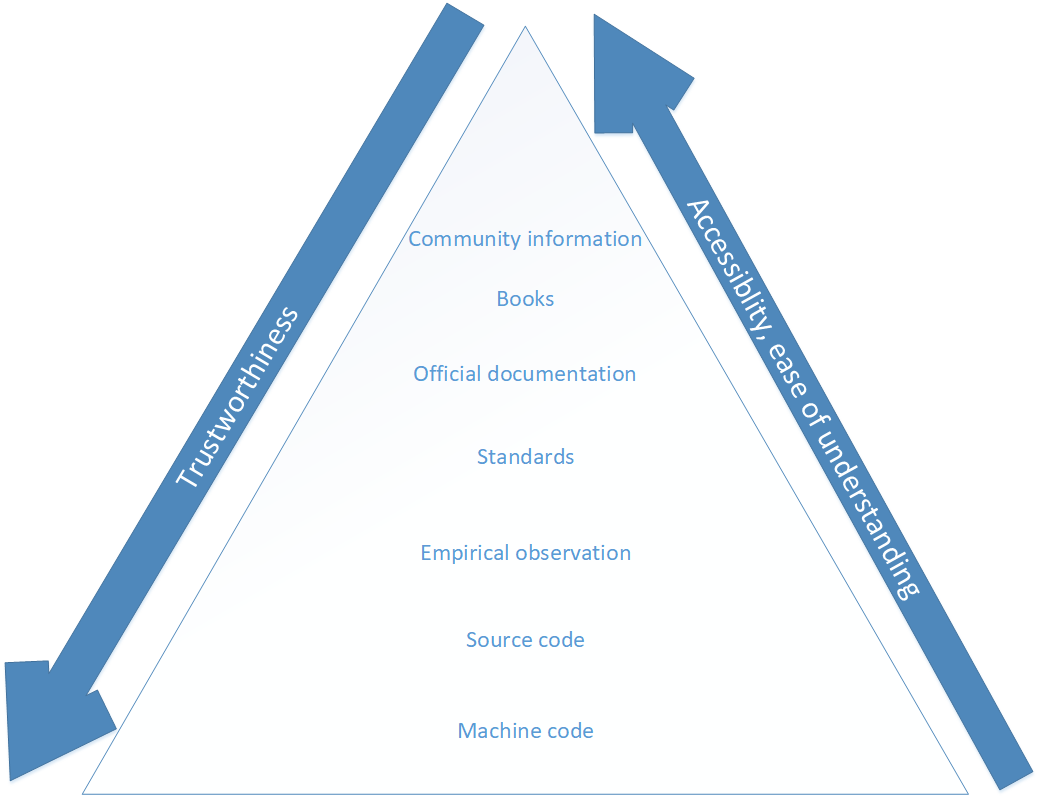
At first, let’s think about what kind of sources we have when we are talking about programming before making it. Personally, I can list these items:

- The actual machine code in the executable or the file that you are examining. This can be considered the primary source in programming. What is inside there is actually executed on your machine so you know that it cannot lie. However, it is very hard to decipher and not very informative. Thus, even though it is the most trustworthy, it is very unfriendly to the person that is trying to learn.
- The source code that was compiled to make the executable or a file. In terms of trustworthiness it is almost as good as machine code and it is a very good source from which to learn because source code is written for humans and lets you understand everything relatively easily. The only downside is that you have to know that the executable/file that you have been actually made from that source code. Projects such as the reproducible builds [2] help with that but still that is not available everywhere and you have to be sure that the source code corresponds to that executable.
- Empirical observation of what system calls the executable is executing, what kind of options are available, what is the output of various commands and so on. This source of information tells you what is apparently available to you as a user but you cannot be sure about what is exactly happening in all cases thus it is not so trustworthy. Also, by using this source information you cannot know what options and commands are exactly available. What if there is a hidden feature or something that is not documented in the output?
- Standards. Now we are entering into the zone where we are not even talking about the actual file/program on your computer. Standards are much more trustworthy than the next item because they are usually governed and released by a rigorous organization such as ISO [3] or ANSI [4]. Also, a lot of deliberation and work goes into making sure everything is correct, orderly, understandable, and that there are no contradictions. On the contrary, they are not so easy to use like the next items because most of the time you have to pay to get the standard. Also, usually they use more technical parlance than the next item.
- Documentation released by the manufacturer, vendor. Quality of information released by the original makers tend to vary a lot. However, it is usually well structured, easily understandable so it is not hard to skim and find the relevant information that you are searching for.

- Books. This source of information tends to be researched more than the item that goes after this one in the list. This is due to the fact that after the book is released, you cannot change it. Also, most of assertions in books need to be backed up by quotes or citations. However, because it is not made by the original company or a group of people that made the executable/file, it is less trustworthy than the previous item. What is more, the topics of books’ chapters have a tendency to be more abstract than the manuals so sometimes it might be not so easy to find information that you are looking for when compared to official manuals.
- Community tutorials, forums, wiki pages, articles. These are the least trustworthy because of the anonymous nature of the Internet. Anyone could write anything and you are never sure if what is written was researched well. There is a reason why no one uses web pages as serious sources of information in the academia. On the other hand, it is very accessible because almost everyone has a mobile phone or a laptop with an internet connection on it nowadays.
We can produce this picture after listing the items:
My point is that everyone should always keep this in mind. Also, now if someone is doing the same mistake I mentioned at the beginning, you should refer them to this article or this hierarchy. I hope this was useful. Please comment if you do not agree with anything mentioned in this post or if you want to discuss.